본 포스팅은 아래 두가지 자료를 기반으로 작성되었습니다.
딥 러닝을 이용한 자연어 처리 입문
많은 분들의 피드백으로 수년간 보완된 입문자를 위한 딥 러닝 자연어 처리 교재 E-book입니다. 오프라인 출판물 기준으로 코드 포함 **약 1,000 페이지 이상의 분량*…
wikidocs.net
밑바닥부터 시작하는 딥러닝 2
이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데이터 처리에 사용하는 딥러닝 기술에 초점을 맞춰 살펴본다. 8장 구성으로 전체를 하나
www.hanbit.co.kr
1. 희소(Sparse) & 분산(Distributed) 표현
1-1. 희소 표현 (Sparse Representation)
희소 표현에 해당되는 대표적인 벡터 표현 방법 중 하나로 원핫인코딩이 있다.
원핫인코딩은 표현하고자 하는 단어의 인덱스의 값만 1이고 나머지 인덱스는 전부 0으로 표현한다.
이렇게 표현할 경우 각 단어 벡터간 유의미한 유사성을 표현할 수 없다.
1-2. 분산 표현 (Distributed Representation)
위의 희소 표현와 달리 분산 표현은 단어의 의미를 다차원 공간에 벡터화한다. (더 자세한 내용은 이후에 다루겠다.)
이 분산 표현을 사용하여 단어 간 의미적 유사성을 벡터화하는 작업을 워드 임베딩이라고 부르며 이렇게 표현된 벡터를 임베딩 벡터라고 한다.
분산 표현은 기본적으로 '비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다' 라는 분포 가설 하에 만들어진 표현 방법이다.
문상훈이라는 단어가 귀엽다, 애교 등의 단어와 함께 주로 등장한다면 분포가설에 따라 해당 내용을 가진 텍스트의 단어들을 벡터화한다면 해당 단어 벡터들은 유사한 벡터값을 가지는 것이다.
이렇게 분산 표현은 분포 가설을 이용해 텍스트를 학습하고 단어의 의미를 벡터의 여러 차원에 분산하여 표현한다.
또한 이렇게 표현되는 벡터들의 차원은 원핫 인코딩 벡터처럼 단어 집합의 크기일 필요가 없어, 벡터의 차원이 상대적으로 저차원을 가지게 된다. 이 때의 차원은 사용자 설정하고 각 차원의 값은 실수값을 갖는다.
이렇게 단어를 표현한다면 단어 벡터 간 유사도를 계산할 수 있게 된다.
2. CBOW (Continuous Bag of Words)
Word2Vec은 위의 분산 표현으로 단어 벡터 간 유의미한 유사도를 반영할 수 있도록 단어의 의미를 수치화하는 방법을 의미하며 이를 위해 CBOW와 Skip-Gram 두가지 방식이 있다.
두 방식의 차이부터 간단히 말하자면
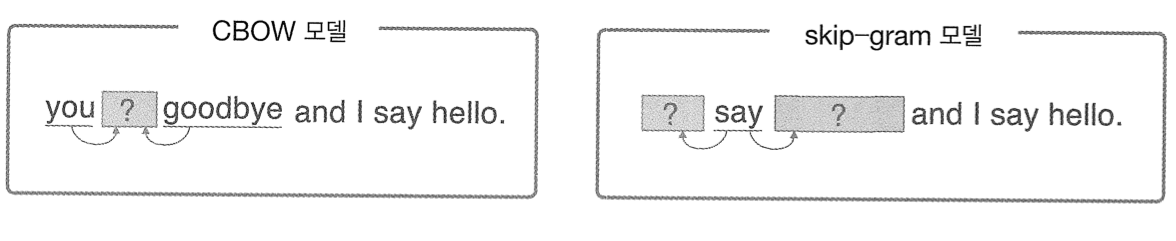
- CBOW : 주변에 있는 단어들을 입력으로 중간에 있는 단어들을 예측하는 방법
- Skip-Gram : 중간에 있는 단어들을 입력으로 주변 단어들을 예측하는 방법
먼저 CBOW부터 다뤄보자.
CBOW 모델은 (맥락 = 주변단어) 로 부터 (타겟 = 중앙 단어)를 추측하기 위한 신경망이다.
간단한 예제로 도식하면 다음과 같다.
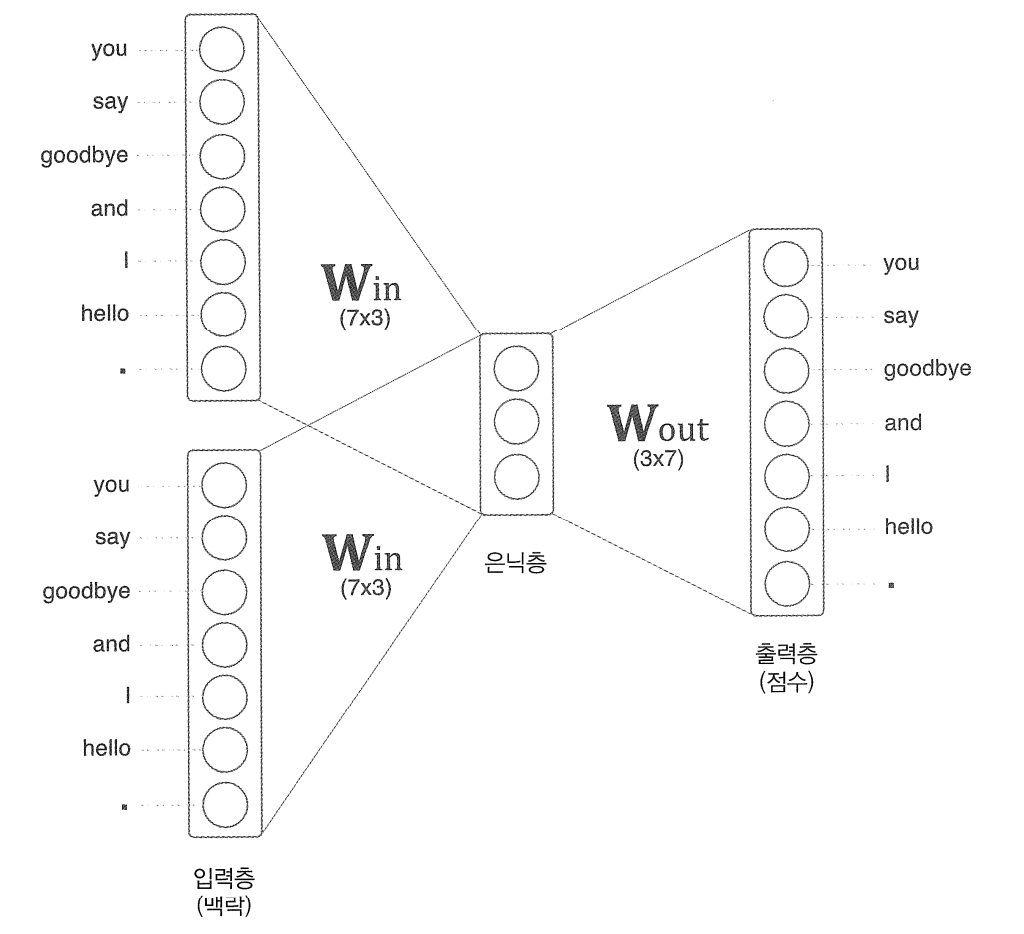
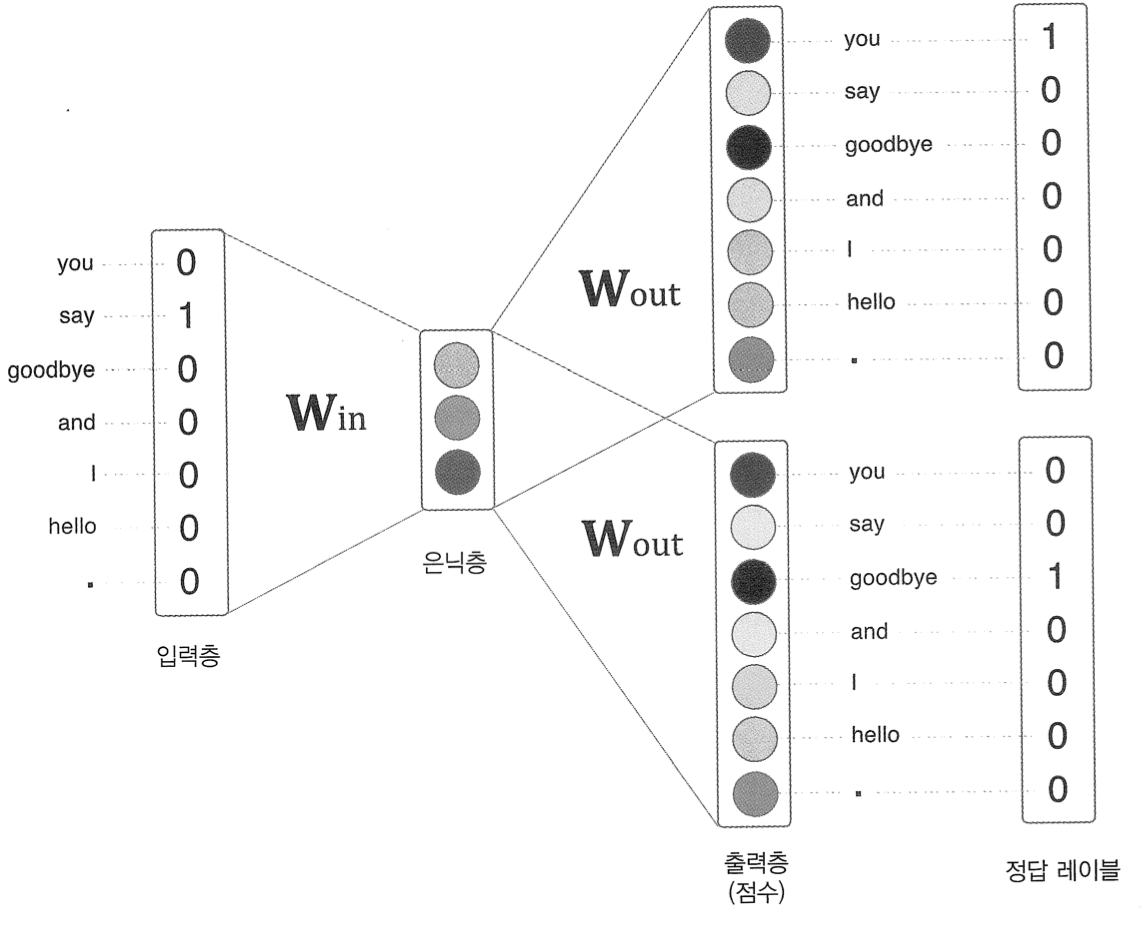
위의 예제의 경우 맥락으로 고려할 단어를 2개로 설정한 경우로, 맥락에 포함시킬 단어가 n개이면 그 입력층도 n개가 된다.
두 입력층 모두 은닉층으로 변환할 때 똑같은 완전연결계층 (Win) 이 처리하고 은닉층에서 출력층으로의 변환은 다른 완전연결계층 (Wout)이 처리한다.
이 때 입력층의 완전연결계층에 의해 변환되는데 입력층이 두개이므로 그 변환값도 두개이다.
이렇게 입력층이 여러개일 경우 전체를 평균한다.
출력층의 뉴런의 갯수는 총 7개인데, 이 뉴런 하나하나가 각각의 단어에 대응된다. 그리고 이는 각 단어의 score를 의미하고 이 값이 높을수록 대응 단어의 출현 확률이 높다는 것을 의미한다. score은 확률로 해석되기 이전의 값이고 이 score에 softmax를 태워야 확률로 해석할 수 있다.
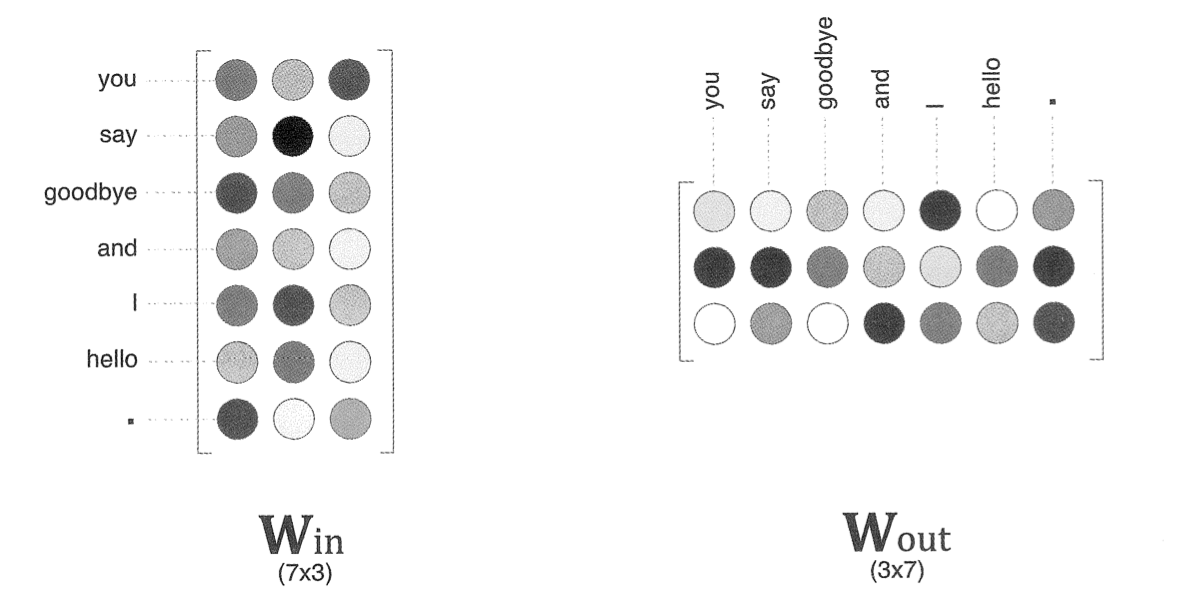
Win의 가중치를 자세히 보면 다음과 같다.

즉, 각 행에는 해당 단어의 분산 표현이 담겨있다고 볼 수 있다. 학습을 진행해 맥락에서 출현하는 단어를 잘 추측할 수 있도록 이 가중치는 업데이트되게 된다.
say라는 타겟을 기준으로 window size=1로 설정해 앞 뒤로 한개씩의 단어, 즉 you와 goodbye를 맥락으로 할 경우 CBOW 모델 신경망 구성은 다음과 같다.
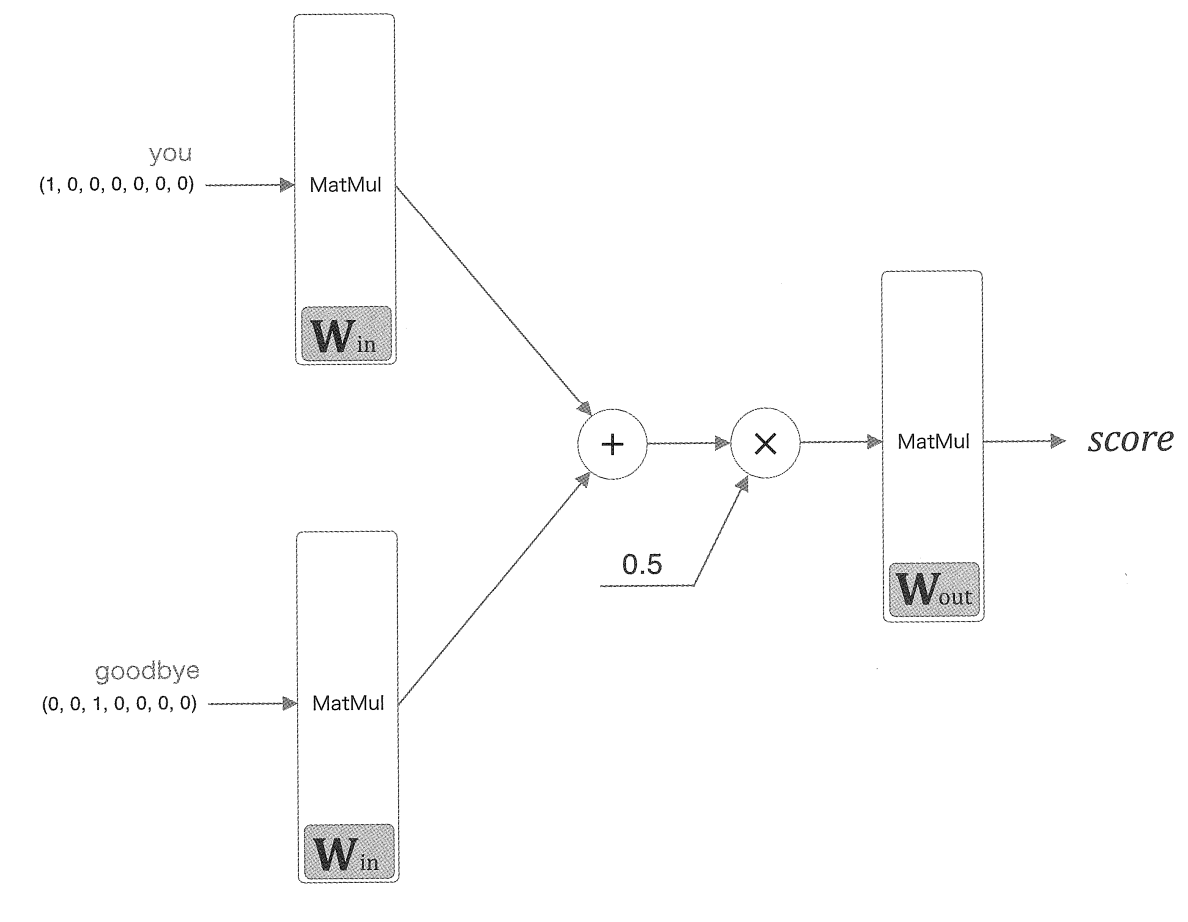
CBOW에서 주목할 점은 모델 추론 과정에서 활성화 함수를 사용하지 않는다는 것이고, 여러 입력층들이 같은 가중치를 공유한다는 점이다.
조금 더 구체적으로 그 학습과정을 알아보자.
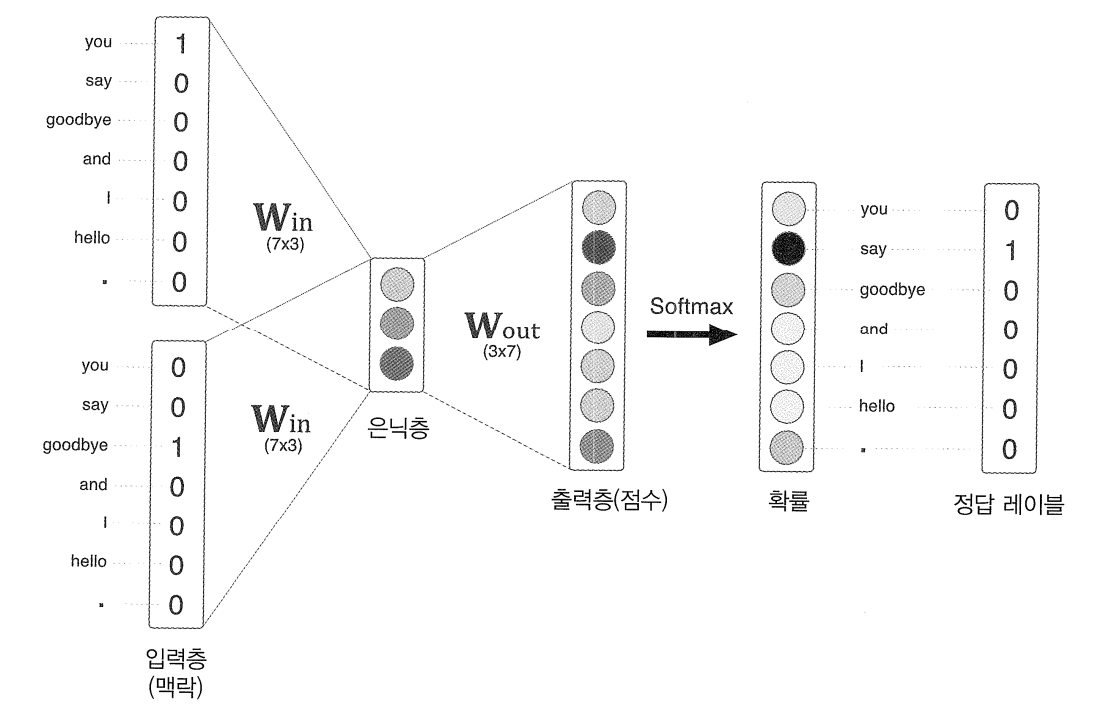
가중치 W in과 W out은 단어 출현 패턴 파악을 위해 학습된 벡터가 담겨있다.
위 신경망의 목적에 대해 다시 상기해보면 구축하고 학습한 모델은 다중 클래스 분류를 진행해야 한다.
따라서 소프트맥스와 교차 엔트로피 오차를 이용한다.
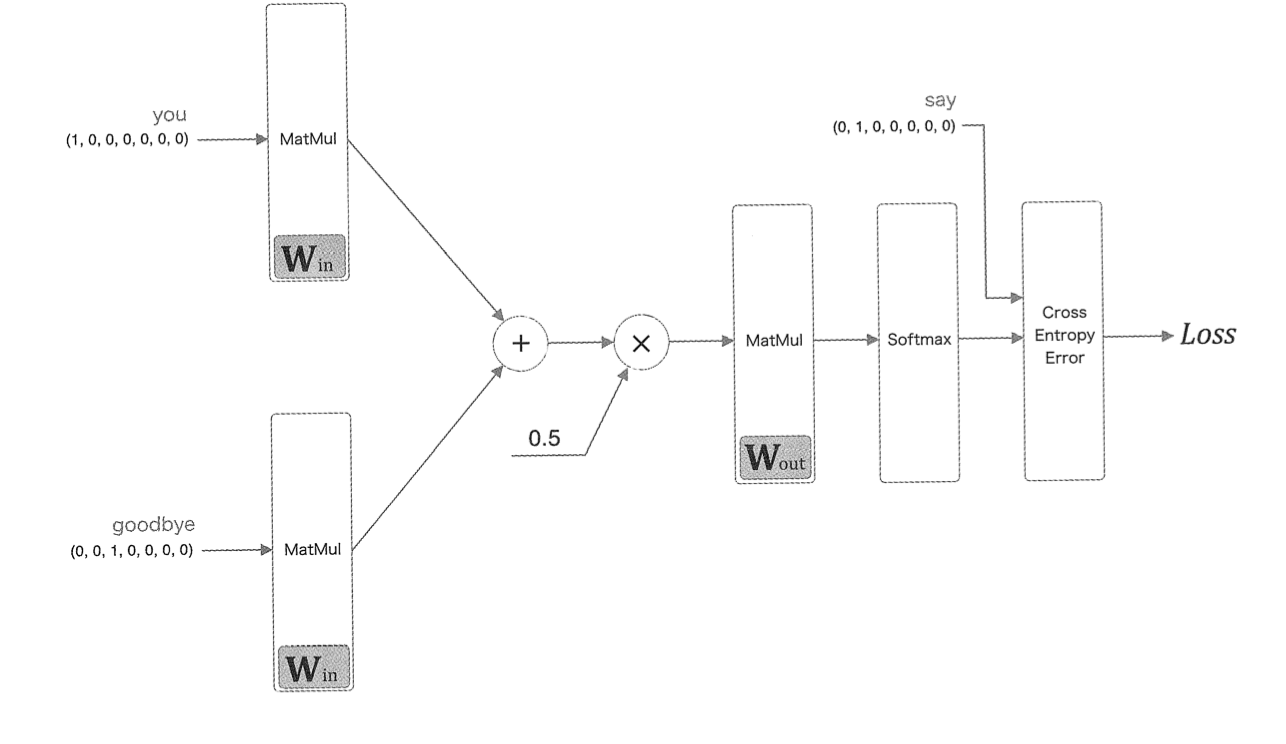
도식 상 분리되어 있는 softmax와 cross entropy error 층은 Sofmax With Loss로 합쳐도 무방하다.
수식으로 표현하면 다음과 같다.
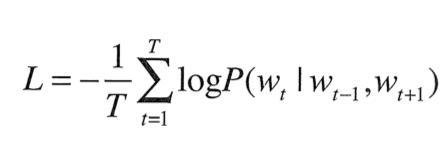
window 사이즈가 1인 경우로 negative log likelihod라고 불린다.
이렇게 정의한 손실함수로 학습을 진행하면 다음과 같은 형태의 입력, 출력 가중치를 가지게 된다.
그렇다면 분산 표현을 위해 어떤 가중치를 선택하는 것이 좋을까?
선택지는 다음과 같다.
- 입력층의 가중치만 사용
- 출력층의 가중치만 사용
- 양쪽 가중치를 모두 사용 (단순 합치는 방법 등)
세 방법 모두 사용가능하지만 많은 연구에서 1안, 즉 입력층의 가중치만을 사용해 분산 표현으로 이용하는 것이 낫다고 밝혔다.
3. Skip - Gram
Skip-Gram은 CBOW와 많은 면에서 비슷하다.
CBOW가 주변 여러 단어(맥락)로부터 중앙의 단어(타깃)을 예측했다면 Skip-Gram은 중앙의 단어로 주변의 여러 단어를 예측한다.
CBOW와 반대로 신경망이 구성되어 있음을 확인할 수 있다.
출력층이 맥락의 수만큼 존재하기에 각 출력층에서 Sofmax with Loss 층을 통해 개별적으로 loss를 구하고 이 loss를 모두 더한 값을 최종 손실로 하여 학습한다.
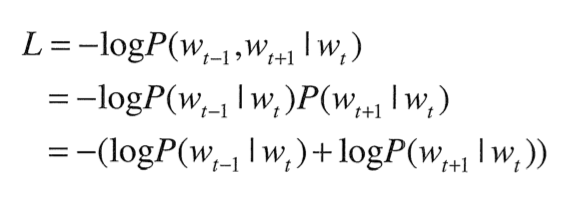
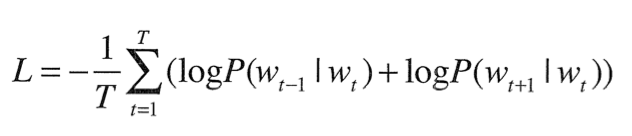
그렇다면 CBOW와 Skip-Gram 중 어떤 모델을 사용해야 할까?
우선 학습속도적인 면에서 Skip-Gram은 맥락의 수만큼 손실을 계산해야 하기에 CBOW보다 그 속도가 느리다.
하지만 말뭉치가 커질수록, 저빈도 단어와 유추 문제에서 Skip-Gram의 성능이 더 높다고 알려져 있다. 통상적으로 Skip-Gram을 사용하는 것이 일반적이다.
4. 실습
gensim 패키지를 이용해 손쉽게 임베딩 벡터로 변환시킬 수 있다.
아래는 영어의 임베딩 벡터 변환으로 xml 문법으로 작성된 영어 코퍼스 데이터를 사용한다.
import re
import urllib.request
import zipfile
from lxml import etree
from nltk.tokenize import word_tokenize, sent_tokenize
urllib.request.urlretrieve("https://raw.githubusercontent.com/ukairia777/tensorflow-nlp-tutorial/main/09.%20Word%20Embedding/dataset/ted_en-20160408.xml", filename="ted_en-20160408.xml")
targetXML = open('ted_en-20160408.xml', 'r', encoding='UTF8')
target_text = etree.parse(targetXML)
# xml 파일로부터 <content>와 </content> 사이의 내용만 가져온다.
parse_text = '\n'.join(target_text.xpath('//content/text()'))
# 정규 표현식의 sub 모듈을 통해 content 중간에 등장하는 (Audio), (Laughter) 등의 배경음 부분을 제거.
# 해당 코드는 괄호로 구성된 내용을 제거.
content_text = re.sub(r'\([^)]*\)', '', parse_text)
# 입력 코퍼스에 대해서 NLTK를 이용하여 문장 토큰화를 수행.
sent_text = sent_tokenize(content_text)
# 각 문장에 대해서 구두점을 제거하고, 대문자를 소문자로 변환.
normalized_text = []
for string in sent_text:
tokens = re.sub(r"[^a-z0-9]+", " ", string.lower())
normalized_text.append(tokens)
# 각 문장에 대해서 NLTK를 이용하여 단어 토큰화를 수행.
result = [word_tokenize(sentence) for sentence in normalized_text]
데이터는 총 273380개의 토큰으로 이뤄져있다.

from gensim.models import Word2Vec
from gensim.models import KeyedVectors
model = Word2Vec(sentences=result, size=100, window=5, min_count=5, workers=4, sg=0)
Word2Vec 모델의 하이퍼라미터는 다음과 같다.
- size = 임베딩된 벡터의 차원
- window = window 크기
- min_count = 단어 최소 빈도 수 (빈도가 적은 단어들은 학습 X)
- workers = 학습을 위한 프로세스 갯수
- sg : 0 = CBOW, 1 = Skip-gram
아래의 코드로 입력한 단어에 대해 가장 유사한 단어들을 출력할 수 있다.
model_result = model.wv.most_similar("man")
print(model_result)
한글에 대해서도 비슷한 과정으로 진행된다.
다만 한글에 맞는 토크나이저와 전처리 과정을 거치게 된다.
데이터는 네이버 영화 리뷰 데이터를 사용한다.
!pip install konlpy
import pandas as pd
import matplotlib.pyplot as plt
import urllib.request
from gensim.models.word2vec import Word2Vec
import tqdm as tqdm
from konlpy.tag import Okt
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings.txt", filename="ratings.txt")
train_data = pd.read_table('ratings.txt')
train_data = train_data.dropna(how = 'any')
리뷰 갯수는 총 199992개이다.
train_data['document'] = train_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")
# 불용어 정의
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
# 형태소 분석기 OKT를 사용한 토큰화 작업 (다소 시간 소요)
okt = Okt()
tokenized_data = []
for sentence in tqdm.tqdm(train_data['document']):
tokenized_sentence = okt.morphs(sentence, stem=True) # 토큰화
stopwords_removed_sentence = [word for word in tokenized_sentence if not word in stopwords] # 불용어 제거
tokenized_data.append(stopwords_removed_sentence)from gensim.models import Word2Vec
model = Word2Vec(sentences = tokenized_data, size = 100, window = 5, min_count = 5, workers = 4, sg = 0)print(model.wv.most_similar("최민식"))
이전까지는 모두 Word2Vec을 학습했지만 pre-training된 word2vec 모델도 존재한다.
구글이 제공하는 Word2Vec 모델은 3백만개의 데이터로 학습되었고 임베딩 벡터의 차원은 300이다.
아래 링크를 통해 모델은 다운받아 위 과정 그대로 사용한다.
https://drive.google.com/file/d/0B7XkCwpI5KDYNlNUTTlSS21pQmM/edit
GoogleNews-vectors-negative300.bin.gz
drive.google.com
Ref
딥 러닝을 이용한 자연어 처리 입문
많은 분들의 피드백으로 수년간 보완된 입문자를 위한 딥 러닝 자연어 처리 교재 E-book입니다. 오프라인 출판물 기준으로 코드 포함 **약 1,000 페이지 이상의 분량*…
wikidocs.net
밑바닥부터 시작하는 딥러닝 2
이 책은 『밑바닥부터 시작하는 딥러닝』에서 다루지 못했던 순환 신경망(RNN)을 자연어 처리와 시계열 데이터 처리에 사용하는 딥러닝 기술에 초점을 맞춰 살펴본다. 8장 구성으로 전체를 하나
www.hanbit.co.kr
'Advance Deep Learning > NLP' 카테고리의 다른 글
| BERT - pytorch 구현 (0) | 2023.02.21 |
|---|---|
| BERT - 이론 (0) | 2023.02.20 |
| Attention is All You Need (Transformer) (0) | 2023.02.13 |
| GPT (0) | 2023.02.10 |