본 포스팅은 아래의 자료와 강의를 기반으로 작성되었습니다.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unla
arxiv.org
17-02 버트(Bidirectional Encoder Representations from Transformers, BERT)
* 트랜스포머 챕터에 대한 사전 이해가 필요합니다.  BERT(Bidire…
wikidocs.net

1. BERT 개요
BERT(Bidirectional Encoder Representations from Transformers)는 구글이 18년에 공개한 pre-tranied 모델이다.
트랜스포머를 이용했으며 위키피디아, BookCorpus의 non-labeled 데이터를 이용해 pre-train되었고 다른 pre-trained 모델과 마찬가지로 fine tuning을 할 수 있다.
BERT는 트랜스포머의 인코더를 쌓아올린 구조로 다음의 두가지 버전이 있다.
- BERT-Base
- L = 12 (# of encoder layers)
- D = 768 (dimension)
- A = 12 (# of self attention head)
- Parameters = 110M (GPT-1과의 비교를 위해 맞춤)
- BERT-Large
- L = 24 (# of encoder layers)
- D = 1024 (dimension)
- A = 16 (# of self attention head)
- Parameters = 340M
2. Subword Tokenizer : WordPiece
BERT는 서브워드 토크나이저를 사용하고 그 중 WordPiece를 사용한다.
WordPiec는 서브워드를 병함해 가는 방식으로 최종 단어 집합을 만든다.
자주 등장하는 단어는 단어 집합에 추가하고, 자주 등장하지 않는 단어는 더 작은 단위의 서브 워드로 쪼개어 단어 집합에 추가된다.
이 집합으로 토큰화를 수행한다.
import pandas as pd
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
result = tokenizer.tokenize('Here is the sentence I want embeddings for.')
print(result)
위 결과를 보면 특정 토큰 앞에 #이 붙어져 있는 것을 볼 수 있다.
이는 BERT의 단어 집합에 embedding이라는 단어가 없어 서브워드로 조깬 뒤, 해당 토큰이 단어 집합에 없음을 나타내고 이후에 다시 embeddings로 복원하기 위해 '##'으로 표시한다.
위 코드에서 embeddings를 제외한 다른 단어들은 모두 단어집합에 존재했기에 ##이 붙지 않았다.
with open('vocab.txt', 'w') as f :
for token in tokenizer.vocab.keys():
f.write(token + '\n')
vocab = pd.read_fwf('vocab.txt', header = None)
vocab
총 30522개의 token으로 구성되어 있음을 확인할 수 있으며, 아래와 같은 특별 토큰들과 매핑값이 있다. 각각이 의미하는 바는 이후 다루겠다.

3. Embedding
BERT에서는 다음 세가지의 임베딩을 진행한다.
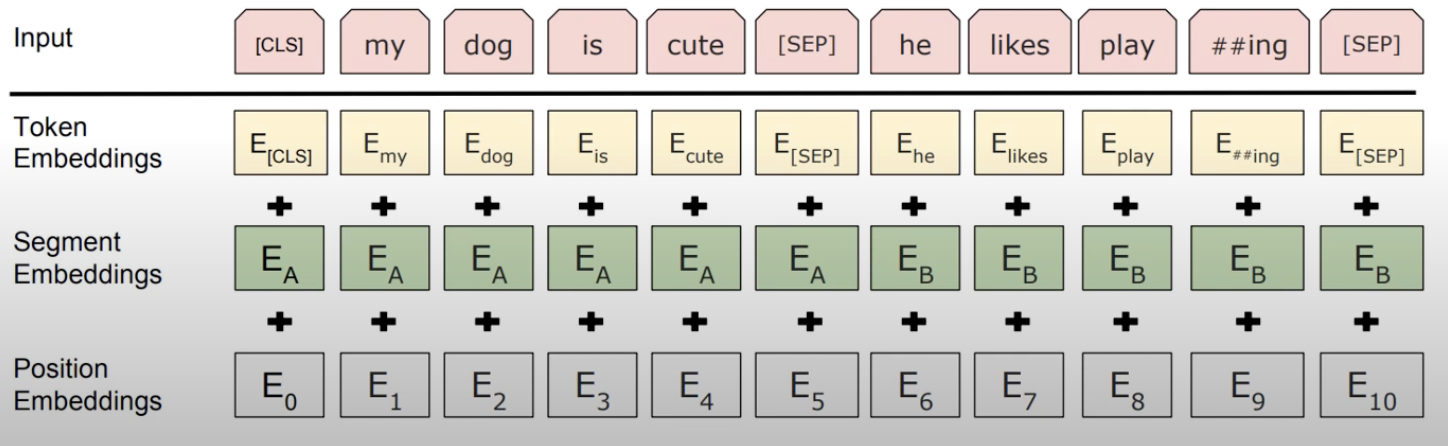
3-1. Contextual Embedding
BERT의 input은 Embedding layer를 지난 768차원의 임베딩 벡터들이다.

위의 도식과 같이 출력 임베딩은 문장의 문맥을 모두 참고해 문맥을 반영한다.
좌측의 CLS, 우측의 love에 해당하는 출력 벡터 모두 다른 단어를 모두 참고하여 출력된다.
이 연산은 BERT의 12개 인코더 layer에서 모두 수행되며 이전 layer의 출력 임베딩이 그대로 다음 layer의 입력 임베딩이 된다.

'문맥을 반영한다' 는 self-attention을 통해 이뤄진다. 이와 관련해서는 transformer 포스팅에서 다루었다.
위 도식과 같이 각 인코더 layer 마다 multi-head self attention과 position-wise feed forward 연산을 수행한다.
3-2. Position Embedding
트랜스포머에서는 Positional Encoding을 통해 단어의 위치를 표현했고, 더 정확히는 주기성을 갖는 사인과 코사인 함수를 통해 위치마다 다른 값을 부여했다.
BERT에서도 position embedding의 목적은 동일하나 그 임베딩을 함수 계산을 통해서가 아닌 학습을 통해 진행한다.
BERT-Base에서는 문장의 최대 길이를 512로 설정하였기에 총 512개의 position embedding 벡터를 학습하게 된다.
3-3. Segment Embedding
BERT의 태스크 중 QA와 같은 두 개의 문장 입력이 필요한 경우가 있다.
이런 경우 두 문장을 구분해야하는데 이를 위해 segment embedding layer를 추가한다.
첫번째 문장은 sentence0, 두번째 문장은 sentence1 임베딩을 수행하고 이렇게 두개의 임베딩 벡터만 사용된다.
주의할 점은 BERT에서의 문장(sentence)는 텍스트 단위로 두 개의 문장이 입력 가능하는 것에서의 문장은 실제 문법 상 여러개의 문장으로 구성될 수 있다.
또한 감성분류와 같이 반드시 두개의 문장을 입력할 필요가 없는 경우, 전체 입력에 sentence0 임베딩만을 더해준다.
4. Pre-Training

위 도식은 세가지 모델의 차이점을 보여준다.
ELMo는 정방향과 역방형 LSTM을 각각 훈련하는 방식으로 bidirectional 언어 모델을 구성한다.
GPT-1은 트랜스포머의 디코더로 이전 단어들로 이후 단어를 예측하는 unidiriectional 언어 모델을 구성한다.
이들과 달리 BERT는 Masked Language Model로 bidirectional을 띈다.
BERT의 가장 큰 특징은 MLM(masked language model)와 NSP(next sentence prediction)이다.
4-1. MLM (Masked Language Model)
BERT는 사전 훈련 시 입력 텍스트의 15% 단어를 랜덤으로 마스킹한다. 그리고 이 마스킹된 단어를 예측하도록 학습된다.

좀 더 정확히 말하자면 다음과 같다.
- 전체 단어의 85%는 MLM 학습에 사용되지 않는다. 15%만이 사용된다.
- 선정된 15% 단어 중 전체의 12%에 해당하는 단어들은 [MASK]로 변경하여 원래 단어를 예측한다.
- original : I love my cat.
- >> I love my [Masked]
- 선정된 15% 단어 중 전체의 1.5%에 해당하는 단어들은 랜덤으로 단어를 변경해 원래 단어를 예측한다.
- original : I love my cat.
- >> I love my dog.
- 선정된 15% 단어 중 전체의 1.5%에 해당하는 단어들은 단어를 변경하지 않지만 BERT는 변경되었는지 알 수 없다. 마찬가지로 원래 단어가 무엇인지를 예측한다.
예시는 다음과 같다.

위의 경우는 한 문장에 세가지 MLM이 모두 있는 경우이다.
마스킹된 dog가 무슨 단어인지 예측해야할 경우, 출력층에 있는 다른 위치의 벡터들은 예측과 학습에 사용되지 않고 오직 dog 위치에 있는 출력층 벡터만을 사용한다. 이는 손실함수가 다른 위치에서의 예측결과는 무시한다는 것을 의미한다.
이 때 예측은 일반적인 예측과 같이 1개의 dense layer에 softmax함수가 추가되는 방식으로 이뤄진다.
4-2. NSP (Next Sentence Prediction)
MLM 외에도 BERT는 두 개의 문장이 입력되면 이 문장이 이어지는 문장인지 아닌지를 맞추는 학습도 진행한다.
이 학습을 위해 실제 일어지는 문장 세트와 랜덤으로 이어붙인 문장 세트를 5:5 비율로 구성하여 학습한다.

이전에서의 special token이 이 학습을 위해 기능한다.
두 문장의 끝에 붙은 [SEP]로 두 문장을 구분할 수 있고 맨 앞의 [CSL] 토큰 위치의 출력층에서 문장이 이어지는지 아닌지 이진분류를 진행한다.
이렇게 NSP를 진행하는 이유는 QA, NLI와 같은 태스크는 두 문장의 관계를 이해하는 것이 중요하기 때문이다.
MLM과 NSP는 따로 학습하는 것이 아닌 두 loss를 합하여 학습이 동시에 이루어진다.
5. Attention Mask
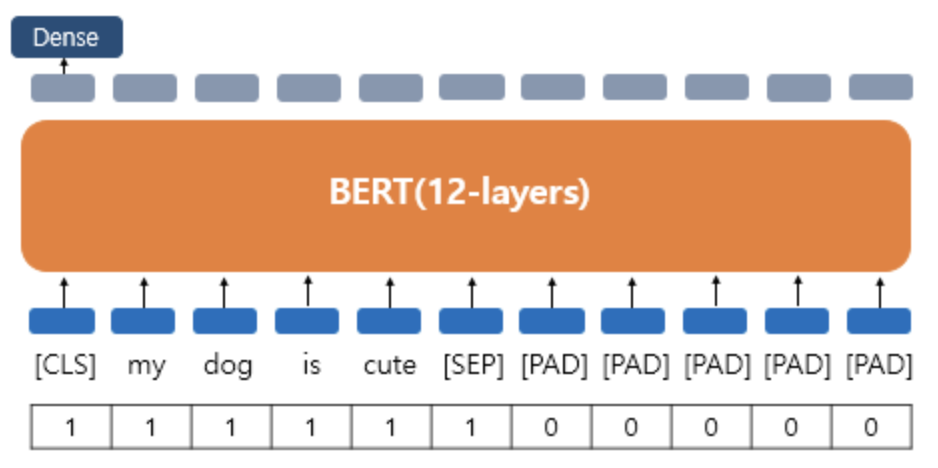
BERT 학습을 진행할 때 attention mask의 추가 시퀀스 입력이 필요하다.
attention mask는 어텐션 연산을 할 때 패딩 토큰에 대해서는 불필요하게 어텐션 연산을 할 필요가 없기에 패딩 토큰임을 알려주기 위해 입력된다.
실제 단어 토큰에는 1, 패딩 토큰에는 0을 부여해 시퀀스를 만들고 BERT의 또다른 입력으로 사용한다.
다음 포스팅에서는 BERT 모델 구현과 fine tuning에 대해 다루겠다.
https://needmorecaffeine.tistory.com/31
BERT - pytorch 구현
본 포스팅은 아래 깃헙과 포스팅을 참고하여 작성되었습니다. https://github.com/codertimo/BERT-pytorch GitHub - codertimo/BERT-pytorch: Google AI 2018 BERT pytorch implementation Google AI 2018 BERT pytorch implementation. Contribute
needmorecaffeine.tistory.com
Ref
17-02 버트(Bidirectional Encoder Representations from Transformers, BERT)
* 트랜스포머 챕터에 대한 사전 이해가 필요합니다.  BERT(Bidire…
wikidocs.net
'Advance Deep Learning > NLP' 카테고리의 다른 글
| Word2Vec - CBOW & Skip-Gram (0) | 2023.02.23 |
|---|---|
| BERT - pytorch 구현 (0) | 2023.02.21 |
| Attention is All You Need (Transformer) (0) | 2023.02.13 |
| GPT (0) | 2023.02.10 |