본 포스팅은 아래 논문과 두 유튜브 강의를 기반으로 작성하였습니다.
1. GPT Basic
GPT는 Generative Pre-trained Transformer의 약자이다. 각각의 의미를 분해해보면 다음과 같다.
1-1. Generative

Generative 모델, 즉 생성 모델은 주어진 학습 데이터를 학습하여 학습 데이터의 분포를 따라는 유사한 데이터를 생성하는 모델을 의미한다. 학습데이터와 유사한 샘플을 뽑아야 하기 때문에 생성 모델은 학습 데이터의 분포를 어느 정도는 알고 있어야 한다.
즉, 생성모델의 핵심은 학습 데이터의 분포를 학습하는 것이며 이것이 잘 이뤄지기 위해서는 충분한 양의 데이터가 확보되어 있어야 한다.
1-2. Pre-Trained
Pre-Trained는 사전 학습된 모델을 의미하며 이를 기반으로 원하는 specific task를 설정하고 어느 정도의 학습으로 해당 task를 구현할 수 있게 한다.
여기서 GPT-1의 핵심적인 특징이 드러난다.
백그라운드부터 말하자면 당연한 얘기지만 text 데이터 중에서 labeled된 데이터는 매우 적고 unlabeled된 데이터는 풍부하다.
따라서 unlabeled된 text corpus에서 Language Model을 pre-training하고 이후에 각 task에 맞게 fine-tuning하게 된다면 많은 이득을 얻을 수 있을 것이다.
하지만 unlabeld데이터는 단어 수준 이상의 정보를 얻기 쉽지 않고, 어떤 optimization objective가 transfer 작업의 효과성을 판단할 수 있을지 불명확하다는 문제점이 있다.
그래서 GPT-1은 Unsupervised Pre-Training 과 Supervised Fine-Tuning을 결합한 Semi-Supervise 접근 방식을 사용한다.
- Goal : 다양한 종류의 task 수행을 위해 약간의 조정만으로 transfer해 사용할 수 있는 representation을 학습
- Two Training Steps
- Unsupervised Pre-Training with Language Model objective function
- Supervised Fine-Tuning (supervised objective에 해당하는 target task에 적용)
- Natural Language Inference
- QA
- Classification
- Semantic Similarity

1-3. Trasformer
LM으로 pre-training할 때 Transformer의 구조를 사용한다. 이 중에서도 decoder 부분만 사용해 trandsformer decoder 블럭을 여러 층으로 쌓게 된다.

2. GPT 상세
이제 GPT에 대해 세부적으로 알아보자. 위 설명과 연속된 내용이다.
Transformer decoder와 block은 아래와 같이 구성되어 있다.

여기서의 masked self attention을 사용하는 것이 이전의 transformer가 self attention을 사용했다는 것과 차이를 가진다.
maksed self attention이란 예측하고자 하는 token 이후의 token은 모두 masking 처리하여 이전의 token만을 사용하는 attention이다.

이렇게 구성된 input과 decoder block의 layer들로 pre-training을 진행하게 된다.
그렇다면 fine-tuning은 어떻게 진행될까?

여기서 C는 labeled 데이터이다.
specific task를 위해 마지막 decoder block의 hidden state에 linear output layer를 추가하고 L2(C)를 최대화하는 objective로 학습한다.
연구자들의 연구 결과 아래의 objective function을 사용하는 것이 가장 좋은 성능을 냈다고 한다.
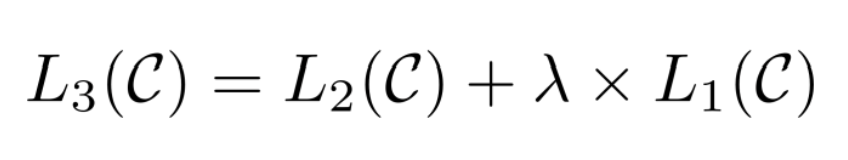
L2만이 아닌 unlabeled data의 pre-train을 위해 사용했던 L1 ojective function도 함께 사용하는 것이다.
이렇게 함께 사용해 다음의 이점을 얻을 수 있었다고 한다.
- Improving generalization of supervised model
- Accelerating convergence
task-specific한 fine tuning을 위해 아래와 같은 input transformation도 함께 제안하고 있다.
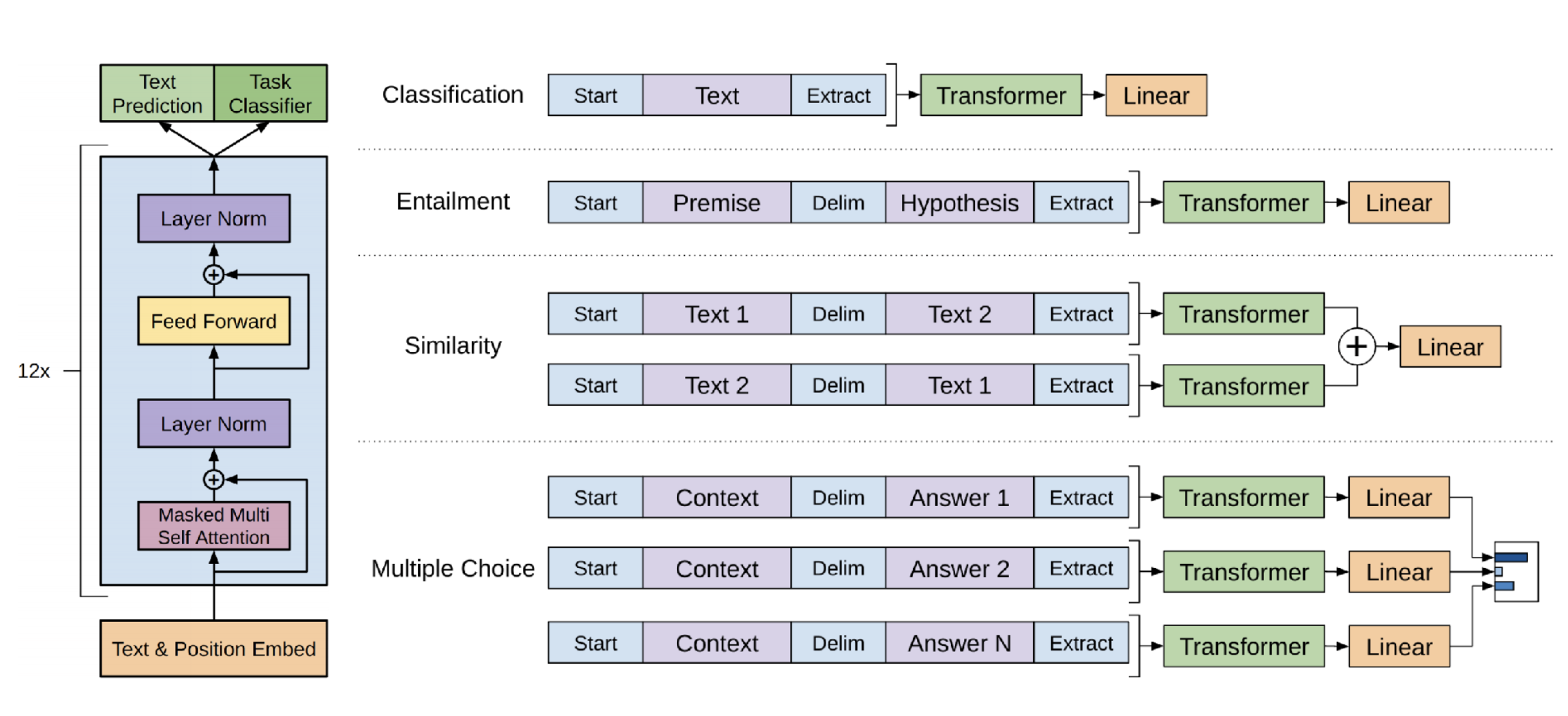
이렇게 구성 및 학습한 후 당시 여러 부문에서 SOTA를 달성하게 된다.
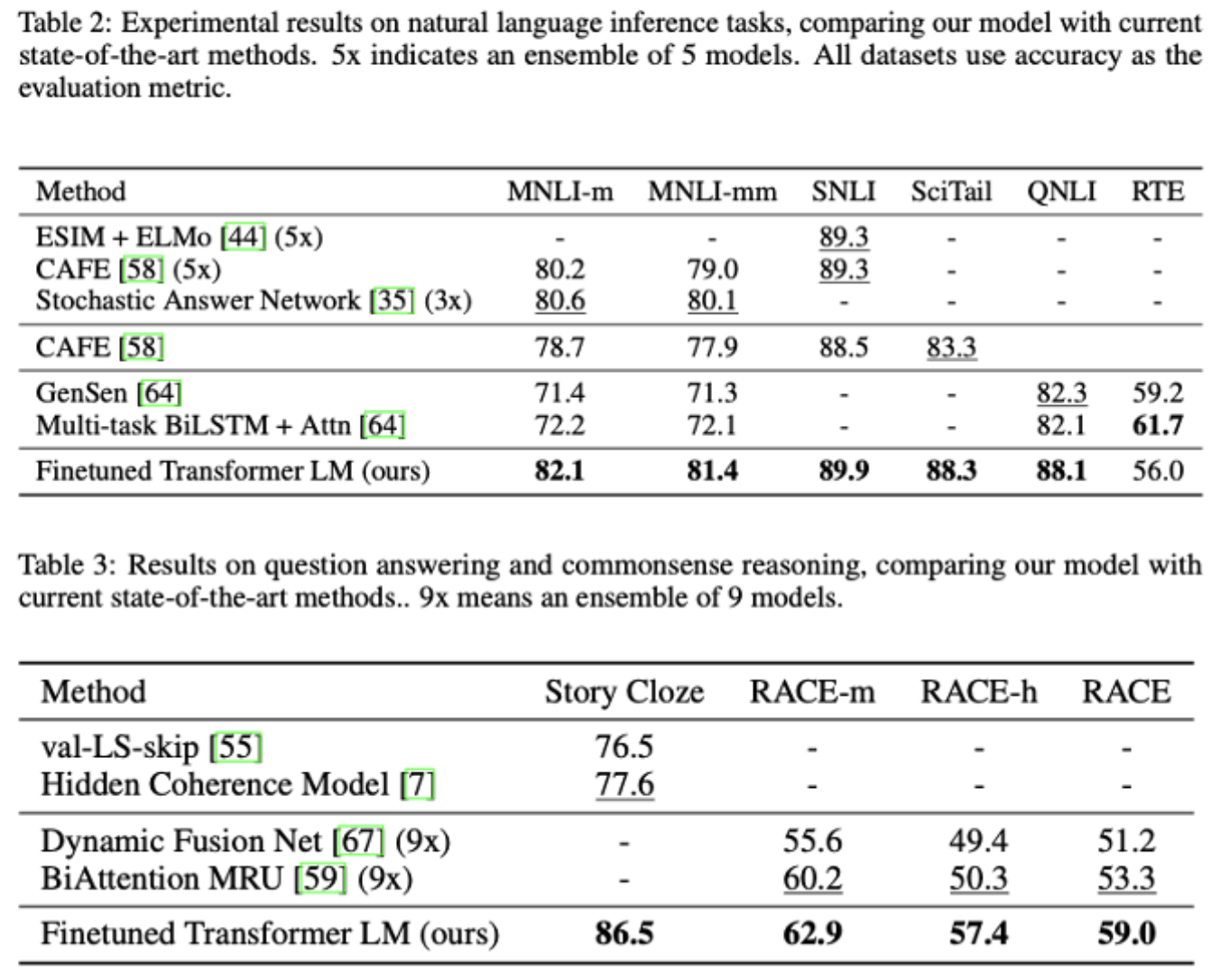
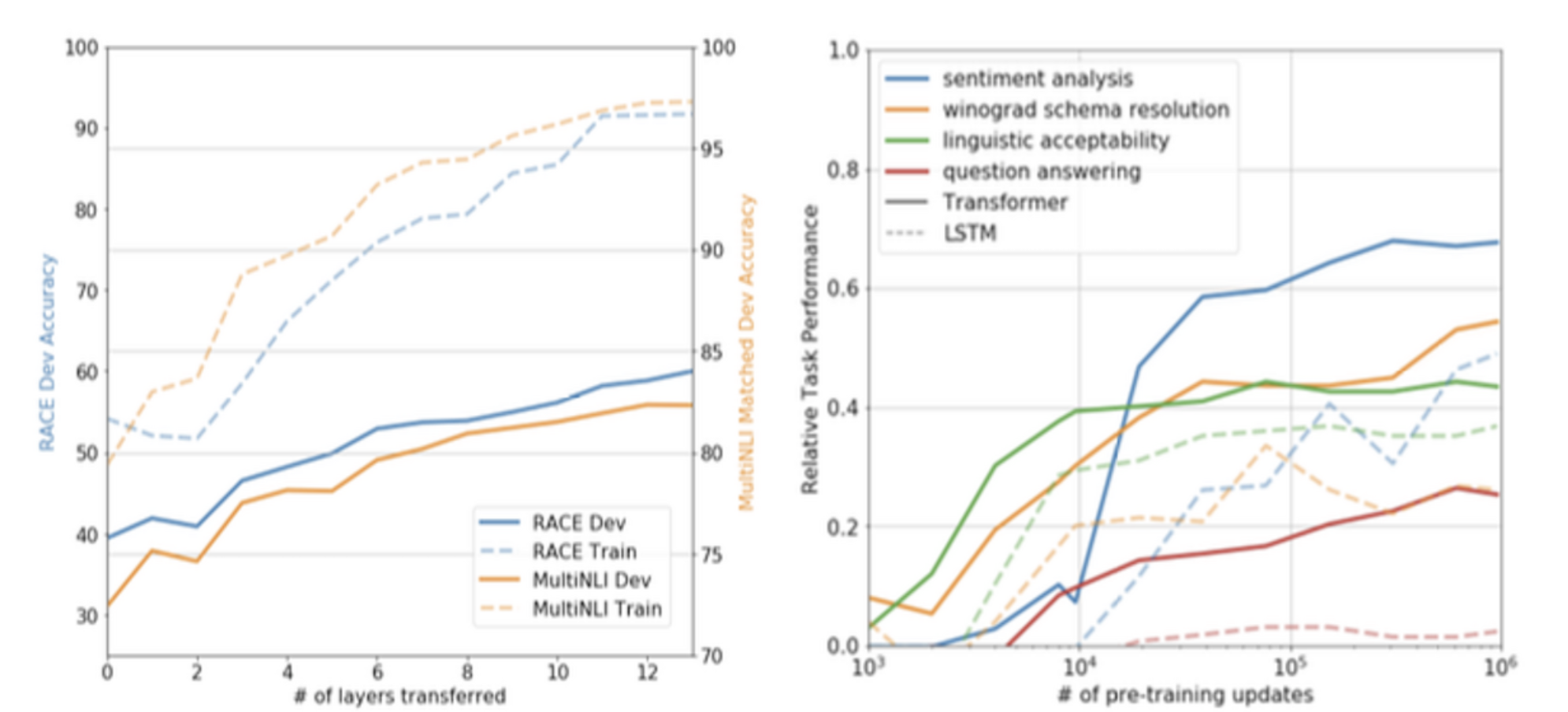
Ref
- 논문 링크
- 강필성 교수님, 고려대 DSBA 연구실 강의
- 허민석, 밑바닥부터 알아보는 GPT-1
- https://minsuksung-ai.tistory.com/12
- https://ainote.tistory.com/17
생성모델(Generative model)이란 무엇일까?
내일이 기말고사라서 간단하게 강의 정리도 해야해서, 오늘은 비지도학습(Unsupervised learning) 중에서 클러스터링(Clustering)과 함께 가장 대표적인 예시 중 하나인 생성모델(Generative model)에 관련해
minsuksung-ai.tistory.com
'Advance Deep Learning > NLP' 카테고리의 다른 글
| Word2Vec - CBOW & Skip-Gram (0) | 2023.02.23 |
|---|---|
| BERT - pytorch 구현 (0) | 2023.02.21 |
| BERT - 이론 (0) | 2023.02.20 |
| Attention is All You Need (Transformer) (0) | 2023.02.13 |